
































 ogłaszają strategiczną współpracę, aby przyspieszyć rozwój centrów danych AI")














Przetwarzanie informacji w chmurze zyskuje w przemyśle na popularności ze względu na konieczność podniesienia i zachowania wysokiej wydajności procesów. Należy jednak wiedzieć, w jakich wypadkach takie przetwarzanie jest przydatne oraz w jakich obszarach powinno znaleźć zastosowanie.
Wielu inżynierów procesów przemysłowych z zadowoleniem wdrożyłoby w swoich działaniach zasadę ?Co działo się w Vegas, zostaje w Vegas? dla swoich systemów, co oznaczałoby, że ?Co dzieje się w dziale operacyjnym, nie wychodzi poza ten dział?. Z punktu widzenia inżynierów procesu systemy i moduły automatyki, elementy sterowania i oprzyrządowanie powinny znajdować się w fabryce. Ten sposób ich organizacji jest bardziej niezawodny i bezpieczny. I tak było jeszcze kilka lat temu. Obecnie nadchodzą zmiany.
Ze względu na konieczność podniesienia wydajności w efekcie rosnącej konkurencyjności rynkowej, firmy coraz częściej decydują się na wykorzystanie przetwarzania danych z systemów monitoringu i sterowania w chmurze, w sieciowych usługach zewnętrznych, co umożliwia gromadzenie danych z produkcji, dokonywanie obliczeń i dostarczanie odpowiednich danych do zarządu, osób odpowiedzialnych za analizę, dostawców, sprzedawców, a w niektórych przypadkach z powrotem do fabryki. Możemy nazywać to Przemysłowym Internetem Rzeczy (IIoT), Przemysłem 4.0 lub zwiększoną kontrolą i pozyskiwaniem danych (SCADA), jednak trzeba mieć świadomość, że ta cyfrowa transformacja produkcji przemysłowej już dawno się rozpoczęła.
Ponieważ takie podejście do organizacji produkcji różni się dramatycznie od stanu rzeczy, jaki ma miejsce od dekad, zadaje się obecnie wiele pytań, takich jak: Co z bezpieczeństwem? Czy łącza sieciowe są niezawodne? Czy też paradoksalnie nie jest to coś, co robimy od dawna, ale pod inną nazwą?
Gdy firmy pokonają okres próbny i zaczną implementacje IIoT i Przemysłu 4.0 na pełną skalę, pojawiają się często kolejne pytania: Jak dużo rzeczy, urządzeń, modułów może być sterowanych za pomocą narzędzi dostępnych w chmurze albo jak duża część danych ma być w niej przetwarzana?
Przetwarzanie danych na potrzeby systemów przemysłowych
Niektórzy propagatorzy technologii przetwarzania danych w chmurze twierdzą, że im więcej danych trafia do chmury, tym lepiej. Jednakże podejście to uwzględnia rzeczywistość przemysłowych systemów sterowania (ICS). Naiwne byłoby implementowanie zarządzania chmurą procesów niskopoziomowych lub ściśle zależnych od czasu albo większości przypadków sterowania nadzorczego. Bezpieczeństwo, szybkość działania i niezawodność sieci, jaką jest Internet, nie może się równać z lokalną siecią fabryki, z komunikacją niezbędną na poziomie obiektowym. Również wielkość danych generowanych przez typowy system przemysłowy konsumowałaby ogromną ilość zasobów chmury, w rezultacie podrażając całą operację.
Jeden z najnowszych trendów w przetwarzaniu danych w chmurze nie ma związku z chmurą, lecz z obrzeżami sieci lokalnych, zakładowych i sieci globalnej Inetrnet. Tzw. edge computing może mieć wiele znaczeń dla różnych osób. Z punktu widzenia chmury IIoT obrzeżami nazywamy granicę, końcowe moduły systemów przemysłowych, jak bramki łączące ją z chmurą. Dla systemu sterowania przemysłowego obrzeżami mogą być urządzenia, takie jak czujnik, siłownik lub jednostka RTU na terenie fabryki, która zbiera dane z wielu urządzeń. Jakkolwiek nie zdefiniujemy pojęcia obrzeża sieci lokalnej i chmury, sedno idei stanowi przetwarzanie i obróbka danych w tych miejscach, co oznacza oszczędność czasu i pieniędzy na filtrowaniu, konwersji i gromadzeniu danych, zanim zostaną one przekazane do kolejnego poziomu analizy.
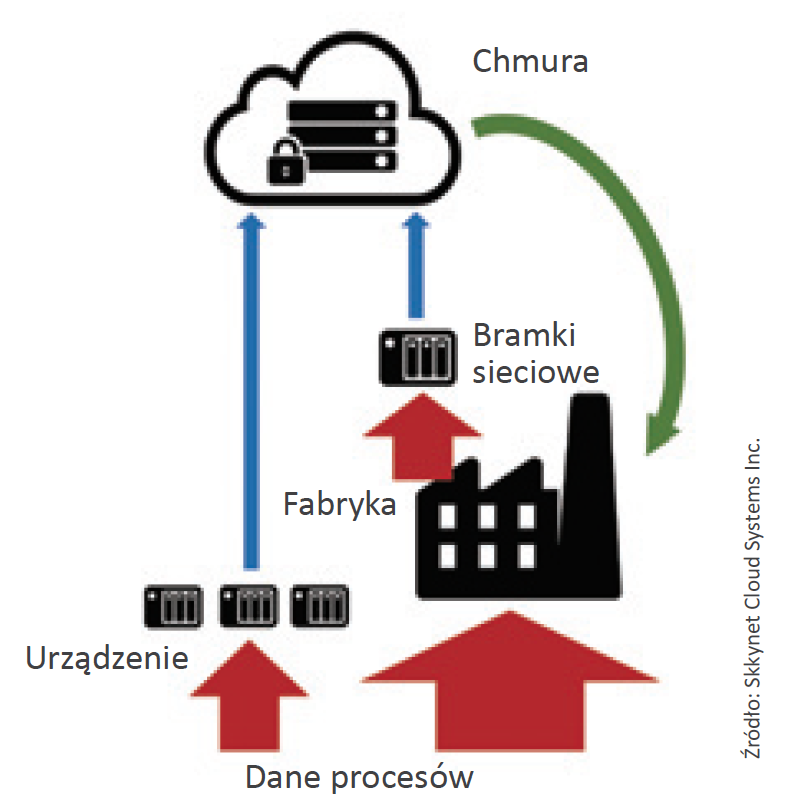
Nie wszystko musi być wykonywane w chmurze. Większość inżynierów automatyków jest zgodna, że dane najlepiej przetwarzać i dostarczać tam, gdzie są one potrzebne. Lokalna obróbka danych sprawia, że odpowiedzi układów są szybsze, przepustowość łączy sieciowych jest wyższa oraz takie podejście redukuje poziom niepewności związany z połączeniem z Internetem. Dlatego w procesie projektowania i organizacji sieciowych systemów sterowania i przetwarzania danych warto wziąć pod uwagę cztery omówione w dalszej części tekstu lokalizacje, w których dane mogą być przetwarzane:
Urządzenie: Dodanie mocy obliczeniowej na poziomie urządzenia może pomóc w ograniczeniu ilości danych, które w późniejszym etapie muszą zostać wysłane do chmury, poprzez filtrowanie i konwersję danych u źródła. W dodatku przetwarzanie danych w urządzeniu może sprawić, że dane różnej postaci, z różnych protokołów, zostaną przetworzone do jednolitej postaci, w jeden wspólny protokół. Oznacza to, że kolejne aplikacje nie muszą rozpoznawać określonych protokołów urządzeń, a dostarczana do nich informacja jest dostępna dla większej liczby klientów.
Fabryka: Tradycyjnie to tutaj realizowana jest większość procedur obróbki danych za pomocą systemu SCADA oraz urządzeń HMI, które zapewniają nadzorczą kontrolę i wizualizację danych. Obecnie, by sprostać nowym wyzwaniom, systemy te coraz częściej używane są do generowania metadanych, takich jak stan urządzenia, stan połączeń, status systemu, jak również śledzenie poziomu produkcji.
Bramka sieciowa: Obróbka danych w bramce to efektywny sposób implementacji oszczędności związanych z redukcją ilości przesyłanych siecią danych i ich konwersją do określonej architektury, która może nie być w stanie wspierać dodatkowych zasobów obliczeniowych. Jeśli organizacja nie chce ingerować w obecny system, dodanie opcji przetwarzania danych w punkcie, w którym opuszczają one fabrykę, ma sens.
Chmura: Jeżeli podjęte są podstawowe działania mające na celu ograniczenie ilości danych, metod ich zarządzania i lepszej jakości wysyłanych z fabryki i urządzeń zdalnych danych, obliczeniowe zasoby chmury mogą zostać efektywnie wykorzystane do gromadzenia takich danych z wielu lokalizacji, przechowywania, analizowania oraz prezentacji zgodnie z wymaganiami klienta.
Najnowsza generacja usług chmury IIoT zapewnia także bezpieczne, obustronne połączenie, co umożliwia odsyłanie z powrotem danych i analiz do autoryzowanych użytkowników w dowolnej lokalizacji. Nie wszystkie usługi chmury to oferują, a trzeba pamiętać, że związane z tym zyski mogą być znaczące. Usługodawcy serwisów w technologii chmury mogą oferować przechowywanie danych na skalę dotąd niespotykaną w wewnętrznych systemach. W połączeniu z szerokimi możliwościami analizy, integracja danych z fabryki oraz usługi w postaci chmury może dostarczyć więcej wiadomości na temat procesu.
Sterowanie i usługi chmury
Najlepsze wykorzystanie nowej generacji usług chmur do celów sterowania przemysłowego będzie zależeć od tego, jak dane w chmurze będą zarządzane oraz w jaki sposób będą odbierane od chmury. Wykorzystanie zasobów na właściwym poziomie do konwersji i optymalizacji danych wysyłanych do chmury zminimalizuje koszty i zapewni szybszy czas obiegu danych po ich analizie z powrotem do fabryki. Ujednolicenie danych pod kątem protokołów sprawi, że dane będą dostępne dla większej liczby klientów i ich aplikacji w chmurze i fabryce. Dni wspomnianego na wstępie podejścia ?co dzieje się w fabryce, zostaje w fabryce? wydają się już policzone. Dostarczanie danych na temat procesu do chmury i otrzymywanie istotnych odpowiedzi to cel wielu projektów dotyczących integracji. Zrównoważenie ilości danych na każdym etapie procesu wydaje się być kluczowe dla pomyślnej implementacji takiego podejścia, a dodanie peryferyjnego przetwarzania danych (edge computing) tam, gdzie jest ono niezbędne, korzystnie wpłynie na cały proces.
Bob McIlvride jest dyrektorem ds. komunikacji w firmie Skkynet Cloud Systems Inc. oraz członkiem CSIA.

